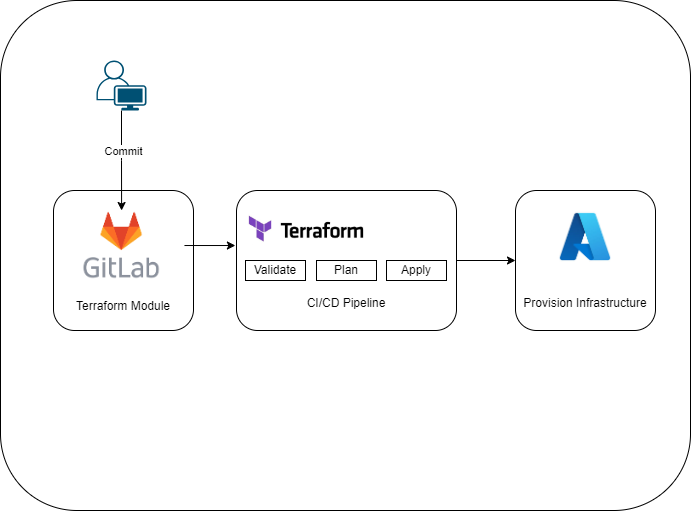
In der heutigen Diskussion konzentrieren wir uns auf die Implementierung einer Terraform-AKSInfrastruktur in der Azure-Cloud unter Verwendung von GitLab CI/CD-Pipelines. Im anschließenden Diagramm wird der Ablauf, den wir in diesem Artikel erörtern werden, veranschaulicht:
Voraussetzungen:
- Az CLI- Tool installiert
- Git- Tool installiert
- Ein Gitlab-Konto eröffnen, geht auch kostenlos
- Azure Account bzw. ein Azure Tenant
Sobald wir ein Azure aktiven Tenant haben und ein Abonnement, müssen wir die Ressourcenanbieter registrieren. Dafür navigieren wir auf das Abonnement >> im Menü links auf Ressourcenanbieter und dann folgende Ressounrcenanbieter müssen registriert werden ‚Microsoft.OperationalInsights‘, ‚Microsoft.ManagedIdentity‘, ‚Microsoft.Network‘, ‚Microsoft.OperationsManagement‘ und ‚Microsoft.ContainerService‘, ‚Microsoft.KubernetesConfiguration‘
Terraform Module
Wir werden einen einfachen Code verwenden, um eine Azure Kubrenetes Service bereitzustellen.
Hier ist der Code: „Der bereitgestellte Code erfolgt ohne jegliche Gewährleistung.”
Es ist wichtig, zunächst das wir ein Azure-Speicherkonto einrichten, um die Terraform-Zustandsdatei sicher zu speichern. Nachdem wir dies eingerichtet haben, vervollständigen wir den Abschnitt #Terraform State mit den erforderlichen Angaben. Dazu gehören die Angabe der Ressourcengruppe wo der Storage Account liegt, der Name selbst vom Storage Account, der Container-Name sowie der Name der Zustandsdatei, in der der Terraform-Status gesichert wird. Hier bitte achten auf die best practices von Microsoft für den Namenskonvention.
provider.tf
terraform {
required_version = ">=1.0"
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "~>3.0"
}
azuread = {
source = "hashicorp/azuread"
version = "~>2.0"
}
azapi = {
source = "Azure/azapi"
version = "1.12.0"
}
random = {
source = "hashicorp/random"
version = "3.6.0"
}
cloudflare = {
source = "cloudflare/cloudflare"
version = ">= 4.1.0"
}
helm = {
source = "helm"
version = ">= 2.9.0"
}
kubernetes = {
source = "kubernetes"
version = ">= 2.18.1"
}
}
}
provider "azurerm" {
features {}
skip_provider_registration = true
}
#Terraform State
terraform {
backend "azurerm" {
resource_group_name = ""
storage_account_name = ""
container_name = ""
key = ""
}
}
main.tf
########################################################################
# Terraform AKS Module
############# To Do List ###############################################
#
# - Storage Account to store the State
# - Storage Account to configure AKS-Backup
# - Azure AD-Groups (RBAC)
# - Azure AD-Users (RBAC)
# - Connect to GitLab
# - Log Analytics Workspace (Monitoring)
#
########################################################################
data "azurerm_client_config" "current" {}
# create Azure Resource Group
resource "azurerm_resource_group" "rg" {
name = var.resource_group_name
location = var.resource_group_location
tags = local.tags
}
# Locals block for hardcoded names
locals {
backend_address_pool_name = "${azurerm_virtual_network.vnet.name}-beap"
frontend_port_name = "${azurerm_virtual_network.vnet.name}-feport"
frontend_ip_configuration_name = "${azurerm_virtual_network.vnet.name}-feip"
http_setting_name = "${azurerm_virtual_network.vnet.name}-be-htst"
listener_name = "${azurerm_virtual_network.vnet.name}-httplstn"
request_routing_rule_name = "${azurerm_virtual_network.vnet.name}-rqrt"
tags = {
environment = "prd"
source = "terraform"
"workload name" = "aks"
Org = "Org"
}
}
# Datasource to get Subnets
data "azurerm_subnet" "kubesubnet" {
name = var.aks_subnet_name
virtual_network_name = azurerm_virtual_network.vnet.name
resource_group_name = azurerm_resource_group.rg.name
}
data "azurerm_subnet" "appgwsubnet" {
name = var.appgw_subnet_name
virtual_network_name = azurerm_virtual_network.vnet.name
resource_group_name = azurerm_resource_group.rg.name
}
# Datasource to get Identity
data "azurerm_user_assigned_identity" "ingress" {
name = "ingressapplicationgateway-${azurerm_kubernetes_cluster.aks.name}"
resource_group_name = azurerm_kubernetes_cluster.aks.node_resource_group
}
# Datasource to get Latest Azure AKS latest Version
data "azurerm_kubernetes_service_versions" "current" {
location = azurerm_resource_group.rg.location
include_preview = false
}
# Virtual network (vnet)
resource "azurerm_virtual_network" "vnet" {
name = var.virtual_network_name
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
address_space = [var.virtual_network_address_prefix]
subnet {
name = var.aks_subnet_name
address_prefix = var.aks_subnet_address_prefix
}
subnet {
name = var.appgw_subnet_name
address_prefix = var.app_gateway_subnet_address_prefix
}
tags = local.tags
}
resource "random_id" "my_id" {
byte_length = 4
}
# Storage Account
resource "azurerm_storage_account" "sa" {
name = "${var.sotrage_account_name}${random_id.my_id.hex}"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
account_tier = "Standard"
account_replication_type = "LRS"
}
# Create Blob container
resource "azurerm_storage_container" "container" {
name = var.sotrage_container_name
storage_account_name = azurerm_storage_account.sa.name
container_access_type = "blob" # Update access type as needed (private, blob, container, or anonymous)
}
resource "azurerm_user_assigned_identity" "aks" {
name = "aks-ide-${var.aks_cluster_name}"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
tags = local.tags
}
resource "azurerm_log_analytics_workspace" "analyticswork" {
name = "k8s-workspace-${random_id.my_id.hex}"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
sku = "PerGB2018"
}
resource "azurerm_log_analytics_solution" "analyticssolut" {
solution_name = "ContainerInsights"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
workspace_resource_id = azurerm_log_analytics_workspace.analyticswork.id
workspace_name = azurerm_log_analytics_workspace.analyticswork.name
plan {
publisher = "Microsoft"
product = "OMSGallery/ContainerInsights"
}
}
# AKS cluster
resource "azurerm_kubernetes_cluster" "aks" {
name = var.aks_cluster_name
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
dns_prefix = var.aks_cluster_name
private_cluster_enabled = var.aks_private_cluster
role_based_access_control_enabled = var.aks_enable_rbac
sku_tier = var.aks_sku_tier
default_node_pool {
name = var.default_node_pool_name
node_count = var.aks_node_count
vm_size = var.aks_vm_size
os_disk_size_gb = var.aks_os_disk_size
max_pods = var.max_pods
max_count = var.max_count
min_count = var.min_count
vnet_subnet_id = data.azurerm_subnet.kubesubnet.id
enable_auto_scaling = var.enable_auto_scaling
}
identity {
type = "UserAssigned"
identity_ids = [azurerm_user_assigned_identity.aks.id]
}
linux_profile {
admin_username = var.cluster_admin
ssh_key {
key_data = jsondecode(azapi_resource_action.ssh_public_key_gen.output).publicKey
}
}
# azure_active_directory_role_based_access_control {
# managed = true
# admin_group_object_ids = [azuread_group.aks_administrators.id]
# }
network_profile {
network_plugin = "kubenet"
dns_service_ip = var.aks_dns_service_ip
service_cidr = var.aks_service_cidr
load_balancer_sku = "standard"
}
azure_policy_enabled = true
oms_agent {
log_analytics_workspace_id = azurerm_log_analytics_workspace.analyticswork.id
}
ingress_application_gateway {
gateway_id = azurerm_application_gateway.appgw.id
}
depends_on = [
azurerm_application_gateway.appgw
]
tags = local.tags
}
resource "azurerm_kubernetes_cluster_node_pool" "user" {
name = var.node_pool_user
kubernetes_cluster_id = azurerm_kubernetes_cluster.aks.id
vm_size = var.aks_vm_size
node_count = 1
vnet_subnet_id = data.azurerm_subnet.kubesubnet.id
max_count = var.max_count
min_count = var.min_count
enable_auto_scaling = true
mode = "User"
tags = local.tags
}
resource "azurerm_public_ip" "pip" {
name = var.pip_name
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
allocation_method = "Static"
sku = "Standard"
tags = local.tags
}
resource "azurerm_application_gateway" "appgw" {
name = var.app_gateway_name
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
sku {
name = var.app_gateway_tiers["tier2"]
tier = var.app_gateway_tiers["tier2"]
capacity = 1
}
gateway_ip_configuration {
name = "appGatewayIpConfig"
subnet_id = data.azurerm_subnet.appgwsubnet.id
}
frontend_port {
name = local.frontend_port_name
port = 80
}
frontend_ip_configuration {
name = local.frontend_ip_configuration_name
public_ip_address_id = azurerm_public_ip.pip.id
}
backend_address_pool {
name = local.backend_address_pool_name
}
backend_http_settings {
name = local.http_setting_name
cookie_based_affinity = "Disabled"
port = 80
protocol = "Http"
request_timeout = 1
}
http_listener {
name = local.listener_name
frontend_ip_configuration_name = local.frontend_ip_configuration_name
frontend_port_name = local.frontend_port_name
protocol = "Http"
}
request_routing_rule {
name = local.request_routing_rule_name
priority = 1
rule_type = "Basic"
http_listener_name = local.listener_name
backend_address_pool_name = local.backend_address_pool_name
backend_http_settings_name = local.http_setting_name
}
lifecycle {
ignore_changes = [
tags,
backend_address_pool,
backend_http_settings,
http_listener,
probe,
request_routing_rule,
]
}
tags = local.tags
}
# AKS Backup Extension
resource "azurerm_kubernetes_cluster_extension" "aks_backup" {
name = var.kubernetes_cluster_extension_name
cluster_id = azurerm_kubernetes_cluster.aks.id
extension_type = "microsoft.dataprotection.kubernetes" # "Microsoft.Azure.Backup" #
#version = "1.0.20"
#release_train = "stable"
configuration_settings = {
"credentials.tenantId" = data.azurerm_client_config.current.tenant_id
"configuration.backupStorageLocation.config.subscriptionId" = data.azurerm_client_config.current.subscription_id
"configuration.backupStorageLocation.config.resourceGroup" = azurerm_storage_account.sa.resource_group_name
"configuration.backupStorageLocation.config.storageAccount" = azurerm_storage_account.sa.name
"configuration.backupStorageLocation.bucket" = azurerm_storage_container.container.name
"backupLocation" = "azure"
"backupInterval" = "1h"
"retentionPolicy" = "30d"
}
depends_on = [azurerm_kubernetes_cluster.aks]
}Variable.tf
In Terraform werden Variablendateien verwendet, um Werte für die in der Terraform-Konfiguration definierten Variablen zu setzen. Dies ermöglicht es die Konfigurationen flexibel und wiederverwendbar zu gestalten. Hier sind einige Schlüsselpunkte zur Verwendung von Variablendateien in Terraform:
Variablendeklaration: In einer Datei namens variables.tf werden Variablen deklariert. Hier geben wir den Namen, den Typ und optional einen Standardwert und eine Beschreibung für jede Variable an.
Wertezuweisung: Die tatsächlichen Werte für diese Variablen werden in einer separaten Datei festgelegt, die oft als terraform.tfvars oder *.auto.tfvars bezeichnet wird. Terraform lädt automatisch alle Dateien, die auf .auto.tfvars oder .tfvars.json enden.
Überschreiben von Werten: Wir können mehrere .tfvars-Dateien haben und beim Ausführen von Terraform-Befehlen spezifische Dateien mit dem -var-file Flag angeben, um bestimmte Werte zu überschreiben z.B.: production.auto.tfvars und dev.auto.tfvars.
- Best Practices: Es gibt keine Einheitslösung für die Verwendung von Variablendateien, da dies von den Anforderungen und Präferenzen Ihres Projekts abhängt. Einige allgemeine Richtlinien sind jedoch:
- Halten Sie Ihre Variablendateien so einfach wie möglich.
- Verwenden Sie
.auto.tfvarsfür Umgebungs- oder geheime Werte, die nicht in die Versionskontrolle aufgenommen werden sollten. - Nutzen Sie Kommentare, um die Verwendung von Variablen zu dokumentieren.
Die Verwendung von Variablendateien ist ein mächtiges Feature in Terraform, das die Wartbarkeit und Skalierbarkeit der Infrastruktur als Code verbessert. Es lohnt sich, sich mit den verschiedenen Möglichkeiten vertraut zu machen und die für das Projekt am besten geeignete Methode zu wählen. Viele benutzen nur die variable.tf für alles.
Persönlich tendiere ich dazu, zwei Dateien anzulegen: eine variable.tf für die Deklaration der Variablen und eine variable.auto.tfvars für die Zuweisung der Werte zu den Variablen.
Es ist sicherzustellen, dass in diesem Artikel ausschließlich Beispielwerte und Standardkonfigurationen verwendet werden.
variable "resource_group_location" {
type = string
default = "West Europe"
description = "Location for all resources."
}
variable "resource_group_name" {
type = string
description = "Resource group name"
default = "Resourcegroup-Name"
}
variable "virtual_network_name" {
type = string
description = "Virtual network name."
default = "Vnet-Name"
}
variable "virtual_network_address_prefix" {
type = string
description = "VNET address prefix."
default = "10.0.0.0/16"
}
variable "aks_subnet_name" {
type = string
description = "Name of the subset."
default = "Subnet-Name"
}
variable "appgw_subnet_name" {
type = string
description = "Name of the subset."
default = "Gateway-Subnet-Name"
}
variable "aks_cluster_name" {
type = string
description = "The name of the Managed Kubernetes Cluster to create."
default = "aks-cluster-name"
}
variable "aks_os_disk_size" {
type = number
description = "(Optional) The size of the OS Disk which should be used for each agent in the Node Pool."
default = 50
}
variable "aks_node_count" {
type = number
description = "(Optional) The initial number of nodes which should exist in this Node Pool."
default = 2
}
variable "max_pods" {
type = number
description = ""
default = 100
}
variable "max_count" {
type = number
description = "(Required only if enable_auto_scaling is set to True)"
default = 4
}
variable "min_count" {
type = number
description = "(Required only if enable_auto_scaling is set to True)"
default = 2
}
variable "aks_sku_tier" {
type = string
description = "(Optional) The SKU tier that should be used for this Kubernetes Cluster. Possible values are Free and Paid (which includes the Uptime SLA)."
default = "Free"
validation {
condition = contains(["Free", "Paid"], var.aks_sku_tier)
error_message = "Invalid SKU tier. The value should be one of the following: 'Free','Paid'."
}
}
variable "aks_vm_size" {
type = string
description = "The size of the virtual machine."
default = "Standard_D3_v2"
}
variable "kubernetes_version" {
type = string
description = "(Optional) Version of Kubernetes specified when creating the AKS managed cluster."
default = "1.19.11"
}
variable "aks_service_cidr" {
type = string
description = "(Optional) The Network Range used by the Kubernetes service."
default = "192.168.0.0/20" # Default Standard AKS IP
}
variable "aks_dns_service_ip" {
type = string
description = "(Optional) IP address within the Kubernetes service address range that will be used by cluster service discovery (kube-dns)."
default = "192.168.0.10" # Default Standard AKS IP
}
variable "aks_private_cluster" {
type = bool
description = "(Optional) Should this Kubernetes Cluster have its API server only exposed on internal IP addresses? This provides a Private IP Address for the Kubernetes API on the Virtual Network where the Kubernetes Cluster is located."
default = true
}
# variable "environment" {
# type = string
# description = "Deployment environment"
# validation {
# condition = contains(["dev", "prod"], var.environment)
# error_message = "Valid value is one of the following: dev, prod."
# }
# }
variable "aks_subnet_address_prefix" {
description = "Subnet address prefix."
type = string
default = "10.0.0.0/22"
}
variable "app_gateway_subnet_address_prefix" {
type = string
description = "Subnet address prefix."
default = "10.0.4.0/27"
}
variable "app_gateway_name" {
description = "Name of the Application Gateway"
type = string
default = "agw-aks-name"
}
variable "node_pool_user" {
description = "Name of the Kubernetes Cluster Node Pool User Name"
type = string
default = "agentpool-name"
}
variable "default_node_pool_name" {
description = "Name of the Kubernetes Cluster Node Pool System Name"
type = string
default = "agentpool-name01"
}
# For a Tier: Basic no charge for the first 10 TB of data processed for a Medium Size
variable "app_gateway_tier" {
description = "Tier of the Application Gateway tier."
type = string
default = "Standard_v2" #Options: "Basic" "Web Application Firewall" "Web Application Firewall V2"
}
variable "app_gateway_tiers" {
type = map(any)
default = {
tier1 = "Standard"
tier2 = "Standard_v2"
tier3 = "WAF"
tier4 = "WAF_v2"
tier5 = "WAF_Medium"
}
}
variable "aks_enable_rbac" {
description = "(Optional) Is Role Based Access Control based on Azure AD enabled?"
type = bool
default = true
}
variable "enable_auto_scaling" {
description = "Default value is false"
type = bool
default = true
}
variable "cluster_admin" {
description = "Cluster Admin User"
type = string
default = "aksadmin"
}
variable "sotrage_account_name" {
type = string
description = "Storage Blob Container"
default = ""
}
variable "sotrage_container_name" {
type = string
description = "Storage Blob Container"
default = ""
}
variable "pip_name" {
type = string
description = "Public IP Name"
default = ""
}
variable "kubernetes_cluster_extension_name" {
type = string
description = "Kubernetes Cluster Extension Name"
default = ""
}variable.auto.tfvars
resource_group_location = ""
resource_group_name = ""
virtual_network_name = ""
virtual_network_address_prefix = ""
aks_subnet_name = ""
appgw_subnet_name = ""
aks_cluster_name = ""
aks_os_disk_size = 50
aks_node_count = 2
max_pods = 30
max_count = 2
aks_vm_size = "Standard_D3_v2"
kubernetes_version = "1.19.11"
aks_service_cidr = "192.168.0.0/20"
aks_dns_service_ip = "192.168.0.10"
aks_private_cluster = true
aks_subnet_address_prefix = ""
app_gateway_subnet_address_prefix = ""
app_gateway_name = ""
node_pool_user = ""
default_node_pool_name = ""
app_gateway_tier = "Standard_v2"
aks_enable_rbac = true / false
enable_auto_scaling = true / false
cluster_admin = ""
sotrage_container_name = ""
sotrage_account_name = ""
pip_name = ""
kubernetes_cluster_extension_name = "aksbackup"
Erstellen eines GitLab-Projekts und Hochladen des Codes:
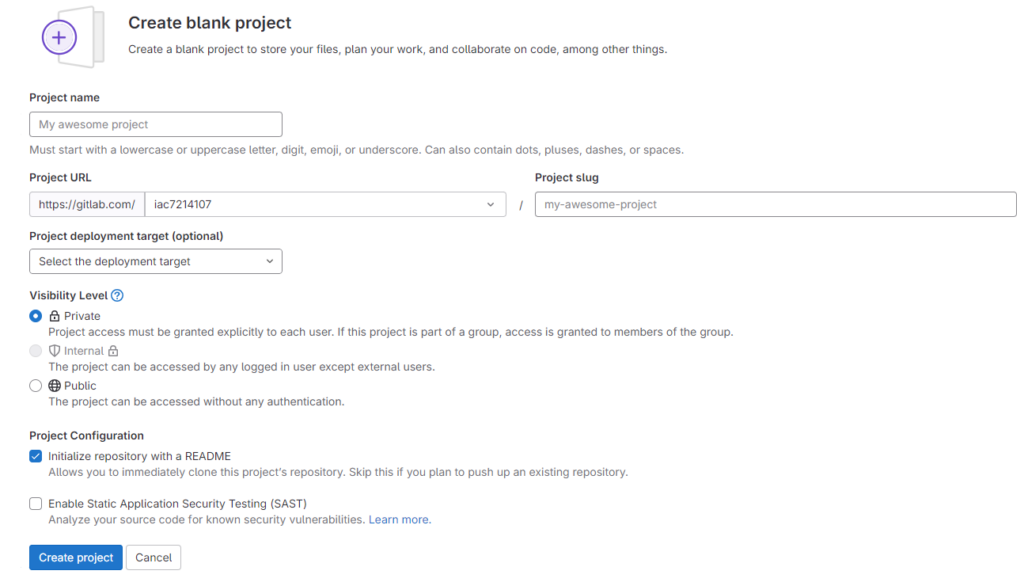
Gehen Sie zu Gitlab.com, melden Sie sich mit Ihren Anmeldeinformationen an, wählen Sie „Neues Projekt“ und „Leeres Projekt erstellen“:
Geben Sie ihm einen Namen und klicken Sie auf die Schaltfläche „Projekt erstellen“:
Klonen Sie das Repository auf Ihren Computer, um Ihren Code hochzuladen:
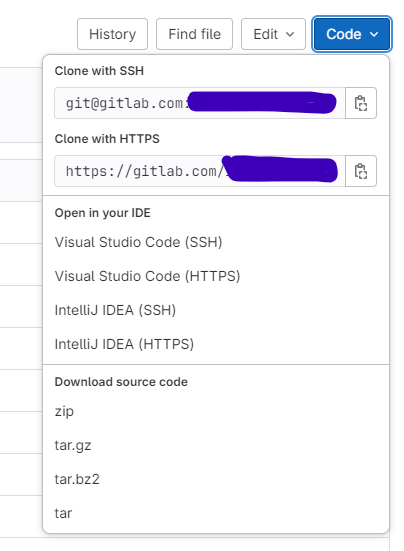
Wir starten unsere Editor-Shell-Sitzung (Visual Studio Code, Powershell, etc..), navigieren zu dem Verzeichnis unserer Wahl, in dem das Repository abgelegt werden soll, und klonen anschließend das neu erstellte Repository mit dem nachstehenden Befehl:
git clone <Repository-URL>Nachdem das Repository erfolgreich auf dem lokalen System geklont wurde, erfolgt die Ablage der zuvor besprochenen Dateien gemäß der folgenden Anweisungen:
git init # Wir initializieren Git
git add . # Um alle Änderungen hinzuzufügen, die übernommen werden sollen (WICHTIG: der Punkt am Ende, muss mitgegeben werden)
git status # Um anzuzeigen, welche Dateien hochgeladen werden
git commit -m "Terraform-Code hinzugefügt" # Um die Änderungen zu übernehmen
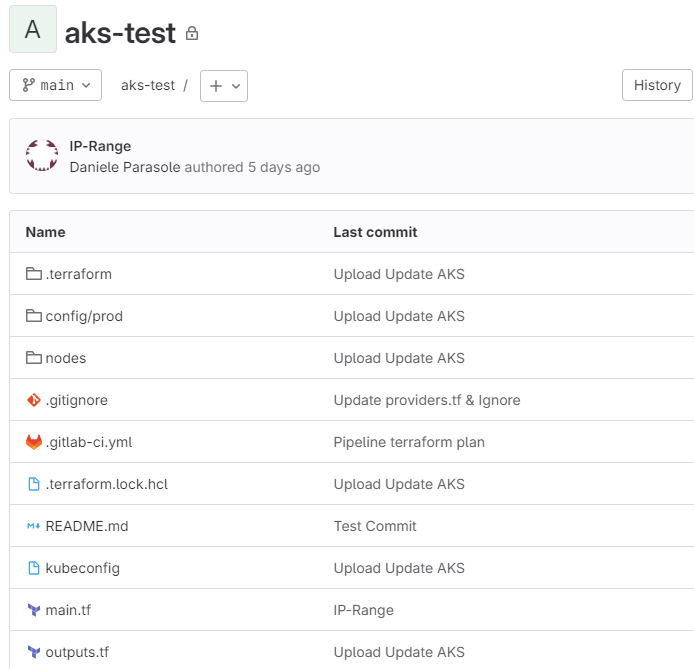
git push # Um die Änderungen in das Repo zu übertragenIm Portal können wir überprüfen, ob die Dateien vorhanden sind:
Vorbereiten der Gitlab-Pipeline
Die nachstehende YAML-Datei definiert die Pipeline-Konfiguration. In dieser Konfiguration werden die einzelnen Schritte festgelegt, die der Prozess zur Bereitstellung des Terraform-Codes durchlaufen soll.
.gitlab-ci.yaml
stages:
- validate
- plan
- apply
default:
image:
name: hashicorp/terraform:latest
entrypoint:
- /usr/bin/env
- "PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
before_script:
- terraform init -reconfigure
cache:
key: terraform
paths:
- .terraform
terraform_validate:
stage: validate
script:
- terraform validate
terraform_plan:
stage: plan
script:
- terraform plan -out plan
artifacts:
paths:
- plan
terraform_apply:
stage: apply
script:
- terraform apply --auto-approve plan
when: manual
allow_failure: false
only:
refs:
- mainDer erste Teil des Skripts gibt die einzelnen Phasen der Pipeline an:
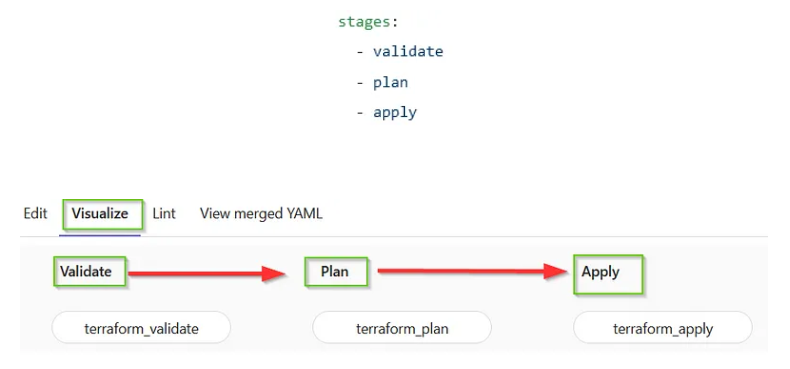
Der zweite Teil zeigt, welches Image für alle Jobs in der Pipeline ausgeführt werden sollen. In diesem Fall verwenden wir ein Image von Hashicorp, das für Terraform bestimmt ist:
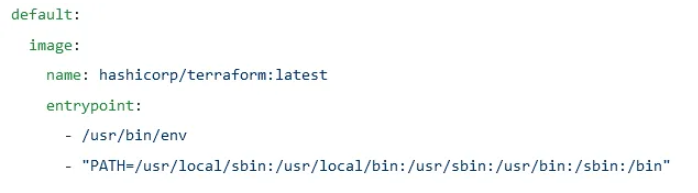
Der dritte Teil zeigt, was vor dem Skript ausgeführt wird. In diesem Fall ist „terraform init“ ein Befehl zum Initialisieren von Terraform, um alle Pakete und Module herunterzuladen, die für die ordnungsgemäße Funktion von Terraform erforderlich sind. Diese Informationen werden in einem Ordner namens .terraform innerhalb des Agenten zwischengespeichert:

Der vierte Teil überprüft, ob das Skript syntaktisch korrekt ist, ob alle Variablen ausgefüllt sind:

Im nächsten Abschnitt wird der Terraform-Plan ausgeführt und die Plandatei als Artefakt generiert, das im nächsten Schritt von Terraform Apply verwendet werden kann:

Der letzte Teil des Skripts wendet die Konfiguration mithilfe der im vorherigen Schritt generierten Plandatei an und muss manuell ausgelöst werden, d. h. jemand muss die Ausführung dieses Auftrags zulassen:

Sobald wir die yaml.datei hochladen werden die Prozesse bzw. die Pipeline gestartet, weil wir die AutoDevops-Funktion aktiviert haben, die jedes Mal eine Pipeline auslöst, wenn ein Commit an diesen Branch erfolgt.